
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- Tkinter
- MariaDB
- 장고
- 논문 리뷰
- Web Programming
- tensorflow
- yaml
- Docker
- 컴퓨터 비전
- 파이썬
- Python
- pytorch
- 그래픽 유저 인터페이스
- GUI
- 딥러닝
- 텐서플로우
- Computer Vision
- POD
- 파이토치
- numpy
- paper review
- OpenCV
- FLASK
- vue.js
- Deep Learning
- 데이터베이스
- 웹 프로그래밍
- Django
- kubernetes
- k8s
- Today
- Total
목록Paper Review (5)
Maxima's Lab
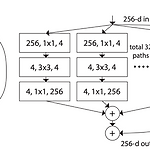 [Paper Review (논문 리뷰)] Aggregated Residual Transformations for Deep Neural Networks (RexNext) + 코드 구현
[Paper Review (논문 리뷰)] Aggregated Residual Transformations for Deep Neural Networks (RexNext) + 코드 구현
안녕하세요, 오늘은 Aggregated Residual Transformations for Deep Neural Networks (https://arxiv.org/pdf/1611.05431.pdf) 위 논문에 대해서 리뷰를 해보고 해당 모델에 대해서 구현해보도록 하겠습니다. RexNeXt는 ResNet의 성능을 개선하기 위해 ResNet과는 다른 방식으로 모델을 구성하였습니다. 이를 위해 ResNet에서 사용된 residual block을 확장하여, 여러 개의 경로를 사용하는 모델 아키텍처인 ResNeXt를 제안하였습니다. RexNeXt의 핵심 아이디어는 Cardinality 입니다. Carninality는 ResNeXt에서 레이어 마다 입력 데이터를 여러 개의 경로로 보내는 개념을 나타냅니다. 예를 들..
 [Paper Review (논문 리뷰)] Attention U-Net: Learning Where to Look for the Pancreas & 코드 구현
[Paper Review (논문 리뷰)] Attention U-Net: Learning Where to Look for the Pancreas & 코드 구현
안녕하세요, 오늘은 Attention U-Net: Learning Where to Look for the Pancreas (https://arxiv.org/pdf/1804.03999.pdf) 위 논문에 대해서 리뷰를 해보도록 하겠습니다. 먼저 Attention U-Net의 전체 구조는 다음과 같습니다. Attention U-Net 모델은 U-Net 아키텍처를 기반으로 하면서, Decoder에서 Attention 메커니즘을 사용하여 성능을 향상시킨 딥러닝 모델입니다. U-Net 모델은 Encoder와 Decoder로 구성되어 있으며, 인코더에서는 이미지를 축소해가며 특성을 추출하고, Decoder에서는 이러한 특성을 기반으로 이미지를 확대하여 Segmentation Mask를 생성합니다. Attention..
안녕하세요, 오늘은 "Free-Form Image Inpainting with Gated Convolution" (https://arxiv.org/pdf/1806.03589.pdf) 위 논문에 대해서 리뷰를 해보도록 하겠습니다. 해당 논문은 이전의 Inpainting 기술에서 보완해야 할 몇가지 문제점을 해결하기 위해 Gated Convolution Neural Network를 사용합니다. 논문에 대한 전반적인 내용들은 다음과 같습니다. 기존의 Inpainting 기술의 문제점 분석 및 Gated Convolution Neural Network의 개념과 작동 방식을 소개하며, Free-From Image Inpainting 모델의 구조와 학습 방법에 대해 상세히 설명합니다. 해당 모델은 Input Ima..
 [Paper Review (논문 리뷰)] U-Net: Convolutional Networks for Biomedical Image Segmentation
[Paper Review (논문 리뷰)] U-Net: Convolutional Networks for Biomedical Image Segmentation
안녕하세요, 오늘은 "U-Net: Convolutional Networks for Biomedical Image Segmentation" 위 논문에 대해서 리뷰를 해보도록 하겠습니다. 먼저 U-Net의 전체 구조에 대해서 살펴보겠습니다. 위의 U-Net의 구조를 보시면 전체적으로 왼쪽, 오른쪽 부분을 나눠서 생각할 수 있습니다. Left side : Convolution(3x3, ReLU), Max Pooling(Downsampling), Crop Right side : Convolution(3x3, ReLU), Convolution(1x1, ReLU), Upsampling, Copy 왼쪽과 오른쪽 부분 모두 Convolution(ReLU)가 동일하게 사용된다는 공통점이 있지만, 왼쪽은 Max Pooli..
 [Paper Review (논문 리뷰)] SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
[Paper Review (논문 리뷰)] SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
안녕하세요, 오늘은 "SegNet : A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation" 위 논문에 대해서 리뷰를 해보도록 하겠습니다. SegNet은 Segmentic Pixel-wise Segmentation을 위한 모델이며, Encoder와 Decoder의 형태로 구성되어 있습니다. 모델의 전체 구조는 다음 그림과 같습니다. 위의 SegNet 아키텍처 내 좌측 Layer 구성이 Encoder, 우측 Layer 구성이 Decoder 입니다. 먼저, Encoder에 대한 내용입니다. [Encoder, 인코더] 위상적으로 VGG16의 Convolutional Layer와 동일하며, Fully Connected Layer 포함 ..