
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- FLASK
- 장고
- pytorch
- 컴퓨터 비전
- vue.js
- 데이터베이스
- Computer Vision
- Django
- yaml
- Docker
- Web Programming
- kubernetes
- 그래픽 유저 인터페이스
- 파이토치
- 텐서플로우
- tensorflow
- POD
- MariaDB
- Tkinter
- OpenCV
- numpy
- 딥러닝
- k8s
- GUI
- 웹 프로그래밍
- 논문 리뷰
- Deep Learning
- 파이썬
- paper review
- Python
- Today
- Total
Maxima's Lab
[Paper Review (논문 리뷰)] Attention U-Net: Learning Where to Look for the Pancreas & 코드 구현 본문
[Paper Review (논문 리뷰)] Attention U-Net: Learning Where to Look for the Pancreas & 코드 구현
Minima 2023. 2. 26. 17:47안녕하세요, 오늘은
Attention U-Net: Learning Where to Look for the Pancreas
(https://arxiv.org/pdf/1804.03999.pdf)
위 논문에 대해서 리뷰를 해보도록 하겠습니다.
먼저 Attention U-Net의 전체 구조는 다음과 같습니다.
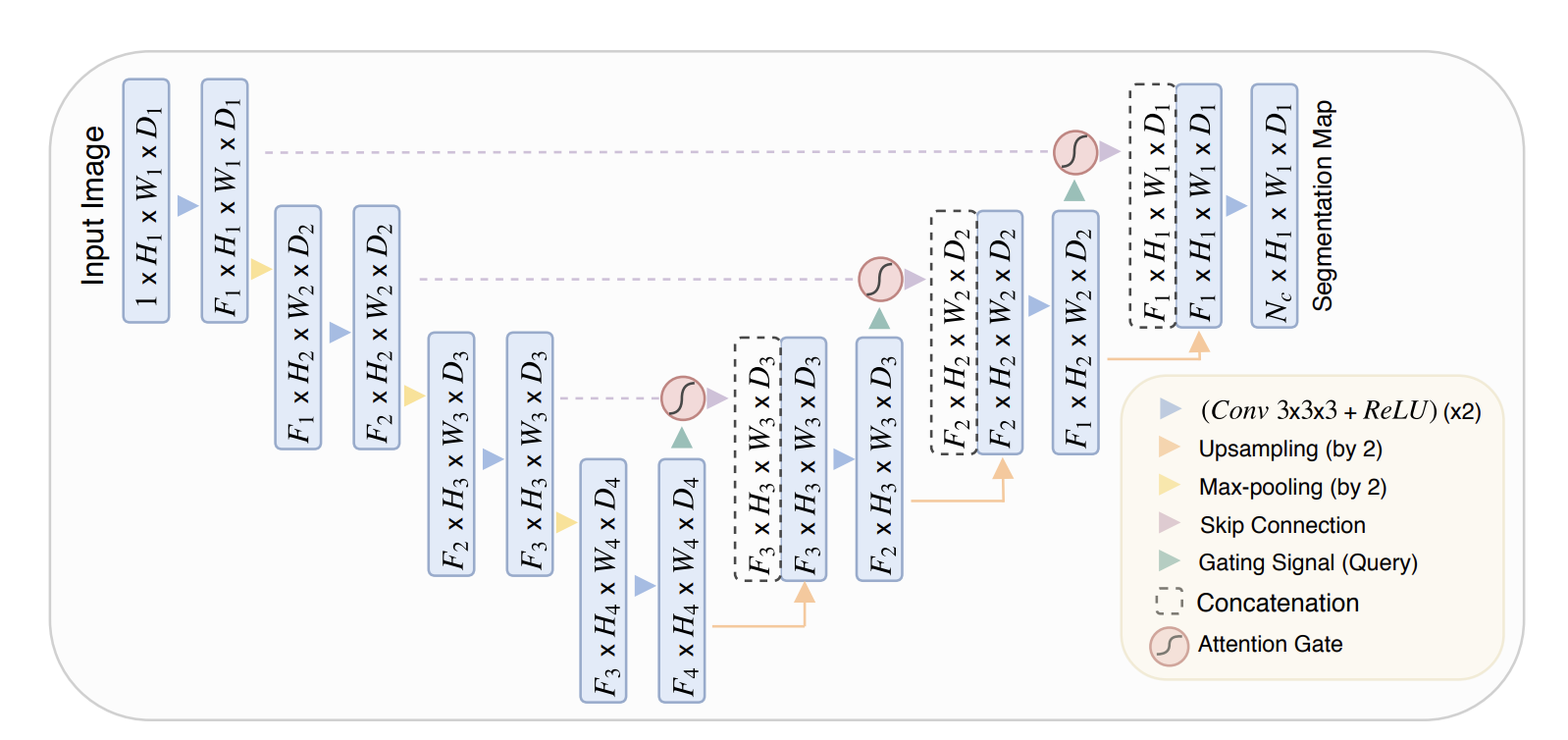
Attention U-Net 모델은 U-Net 아키텍처를 기반으로 하면서, Decoder에서 Attention 메커니즘을 사용하여 성능을 향상시킨 딥러닝 모델입니다.
U-Net 모델은 Encoder와 Decoder로 구성되어 있으며, 인코더에서는 이미지를 축소해가며 특성을 추출하고, Decoder에서는 이러한 특성을 기반으로 이미지를 확대하여 Segmentation Mask를 생성합니다. Attention U-Net 모델에서는 이러한 U-Net 구조에 더해, Decoder에서 Attention 메커니즘을 사용해서 성능을 더욱 향상시킵니다.
Attention U-Net 모델의 인코더는 일반적인 U-Net 모델과 거의 동일합니다. 입력 이미지는 2개의 Convolution Block을 거친 후 Max Pooling 연산으로 크기를 절반으로 줄입니다. 이후 인코더는 4개의 Convolution Block을 거치며, 각 블록에서는 Convolution, Batch Normalization, ReLU 활성화 함수를 사용합니다. 이를 통해 이미지의 특성을 접차 추출하고, 크기를 절반으로 줄여 Decoder로 전달합니다.
Decoder는 Encoder와 거의 대칭된 구조를 가지고 있습니다. 하지만 Attention U-Net 모델에서는, U-Net 모델에서는 각 레이어에서 단순히 크기를 늘리고 채널을 합치는 대신, Attention Block을 추가하여 정보를 합치게 됩니다. 이를 위해, Decoder의 각 레이어에서는 이전 레이어와 Attention Block을 추가하여 정보를 합치게 됩니다. 이를 위해, Decoder의 각 레이어에서는 이전 레이어와 Attention Block이 연결되어 Encoder에서의 출력과의 관계를 모델링하게 됩니다. Decoder의 각 레이어에서는 Upsampling Block, Convolution Block, Attention Block이 추가되어 있으며, 이를 통해 Decoder에서 Encoder의 출력에 더 많은 가중치를 부여하도록 합니다.
다음은 Attention U-Net의 모델을 Pytorch 프레임 워크를 사용해서 구현한 결과입니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(ConvBlock, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv(x)
return xnn.BatchNorm2d 함수는 Batch Normalization 레이어를 적용하여 입력 데이터를 평균 0, 분산 1로 정규화하여 훈련을 안정화하는 데 사용됩니다. 이를 통해 모델의 성능을 향상시키고, 과적합을 방지합니다.
** nn.ReLU(inplace=True)에서 inplace=True를 사용하면 입력 텐서 자체를 변경하여 새로운 텐서를 만들지 않고 다음 계층으로 전달 할 수 있습니다.
class UpSamplingBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(UpSamplingBlock, self).__init__()
self.up = nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2)
def forward(self, x):
x = self.up(x)
return x
class AttentionBlock(nn.Module):
def __init__(self, F_g, F_l, F_int):
super(AttentionBlock, self).__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.relu = nn.ReLU(inplace=True)
def forward(self, g, x):
g1 = self.W_g(g)
x1 = self.W_x(x)
psi = self.relu(g1 + x1)
psi = self.psi(psi)
x = x * psi
return x위의 Class에서 self.W_g와 self.W_x는 1x1 Convolution 레이어의 시퀀스로, 각각 입력 이미지(g) 디코더에서의 입력 이미지(x)를 F_int 차원으로 임베딩합니다. 이를 통해 각 픽셀의 입력 이미지와 인코더에서의 출력 이미지를 다른 공간에서 유사한 벡터로 임베딩하고, Attention map을 생성하기 위한 가중치로 사용합니다.
class AttU_Net(nn.Module):
def __init__(self, in_channels=3, out_channels=1):
super(AttU_Net, self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.Conv1 = ConvBlock(in_channels, 64)
self.Conv2 = ConvBlock(64, 128)
self.Conv3 = ConvBlock(128, 256)
self.Conv4 = ConvBlock(256, 512)
self.Conv5 = ConvBlock(512, 1024)
self.Up5 = UpSamplingBlock(1024, 512)
self.Att5 = AttentionBlock(F_g=512, F_l=512, F_int=256)
self.Up_conv5 = ConvBlock(1024, 512)
self.Up4 = UpSamplingBlock(512, 256)
self.Att4 = AttentionBlock(F_g=256, F_l=256, F_int=128)
self.Up_conv4 = ConvBlock(512, 256)
self.Up3 = UpSamplingBlock(256, 128)
self.Att3 = AttentionBlock(F_g=128, F_l=128, F_int=64)
self.Up_conv3 = ConvBlock(256, 128)
self.Up2 = UpSamplingBlock(128, 64)
self.Att2 = AttentionBlock(F_g=64, F_l=64, F_int=32)
self.Up_conv2 = ConvBlock(128, 64)
self.Conv = nn.Conv2d(64, out_channels, kernel_size=1)
def forward(self, x):
# Encoder
x1 = self.Conv1(x)
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
x3 = self.Maxpool(x2)
x3 = self.Conv3(x3)
x4 = self.Maxpool(x3)
x4 = self.Conv4(x4)
x5 = self.Maxpool(x4)
x5 = self.Conv5(x5)
# Decoder
d5 = self.Up5(x5)
x4 = self.Att5(g=d5, x=x4)
d5 = torch.cat((x4, d5), dim=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
x3 = self.Att4(g=d4, x=x3)
d4 = torch.cat((x3, d4), dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
x2 = self.Att3(g=d3, x=x2)
d3 = torch.cat((x2, d3), dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
x1 = self.Att2(g=d2, x=x1)
d2 = torch.cat((x1, d2), dim=1)
d2 = self.Up_conv2(d2)
out = self.Conv(d2)
return out
지금까지,
Attention U-Net: Learning Where to Look for the Pancreas
위 논문에 대해서 알아보고, 해당 모델을 직접 구현해보았습니다.


