
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- GUI
- tensorflow
- yaml
- 그래픽 유저 인터페이스
- Computer Vision
- Deep Learning
- 데이터베이스
- 딥러닝
- OpenCV
- pytorch
- 파이토치
- Python
- Web Programming
- 논문 리뷰
- MariaDB
- 장고
- 컴퓨터 비전
- FLASK
- 웹 프로그래밍
- kubernetes
- numpy
- Django
- Docker
- paper review
- POD
- Tkinter
- 파이썬
- 텐서플로우
- vue.js
- k8s
- Today
- Total
Maxima's Lab
[Deep Learning (딥러닝)] Label Smoothing 개념 + Tensorflow 2 적용 본문
안녕하세요, 오늘은 Label Smoothing의 개념에 대해서 알아보고 알아보겠습니다.
Label Smoothing (라벨 스무딩)이란, 딥러닝 분류 모델을 학습 시 사용하는 정규화 기법이며, 모델 학습 시 과확신을 방지하기 위해 사용합니다.
이를 위해 다음과 같이 One-Hot Encoding Labeling을 조정하게 됩니다.
(Ex) : [1, 0, 0, 0, 0] ==> [0.8, 0.05, 0.05, 0.05, 0.05]
위와 같이 적용하기 위해서는 Categorical Crossentropy 함수를 수정해야 합니다.
def label_smoothing_loss(y_true, y_pred, label_smoothing=0.1):
num_classes = tf.cast(tf.shape(y_true)[-1], tf.float32)
y_true_smoothed = y_true * (1.0 - label_smoothing) + label_smoothing / num_classes
loss = tf.keras.losses.categorical_crossentropy(y_true_smoothed, y_pred)
return loss
아래는 ciafr10 데이터 셋을 활용하여, 모델을 학습 후 Test Dataset에 대해 Max Score 값들을 히스토그램으로 시각화 한 결과 입니다.
순서대로, Label Smoothing 미 적용, label_smoothing=0.1, 0.2, 0.3, 0.4 입니다.
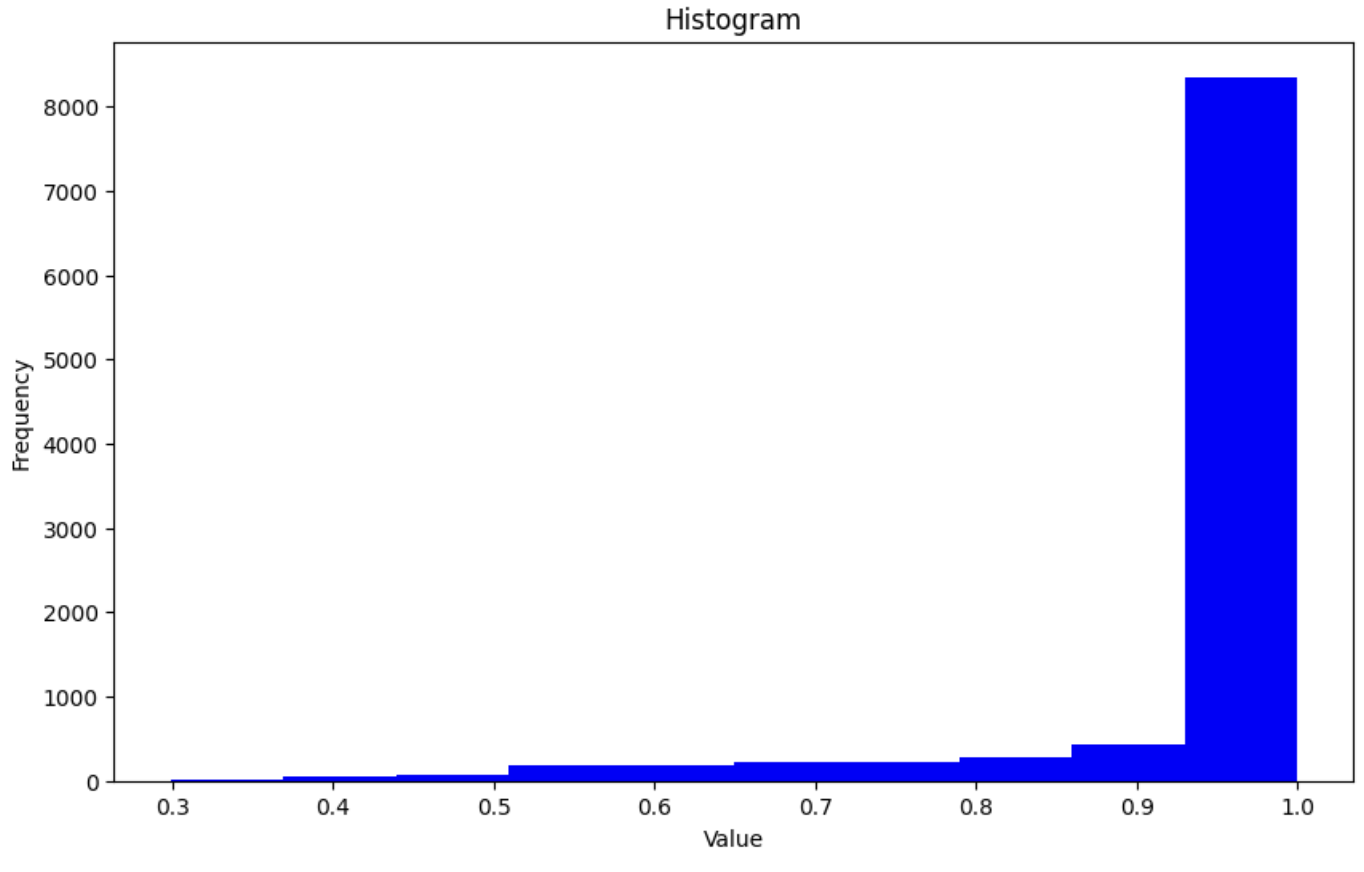
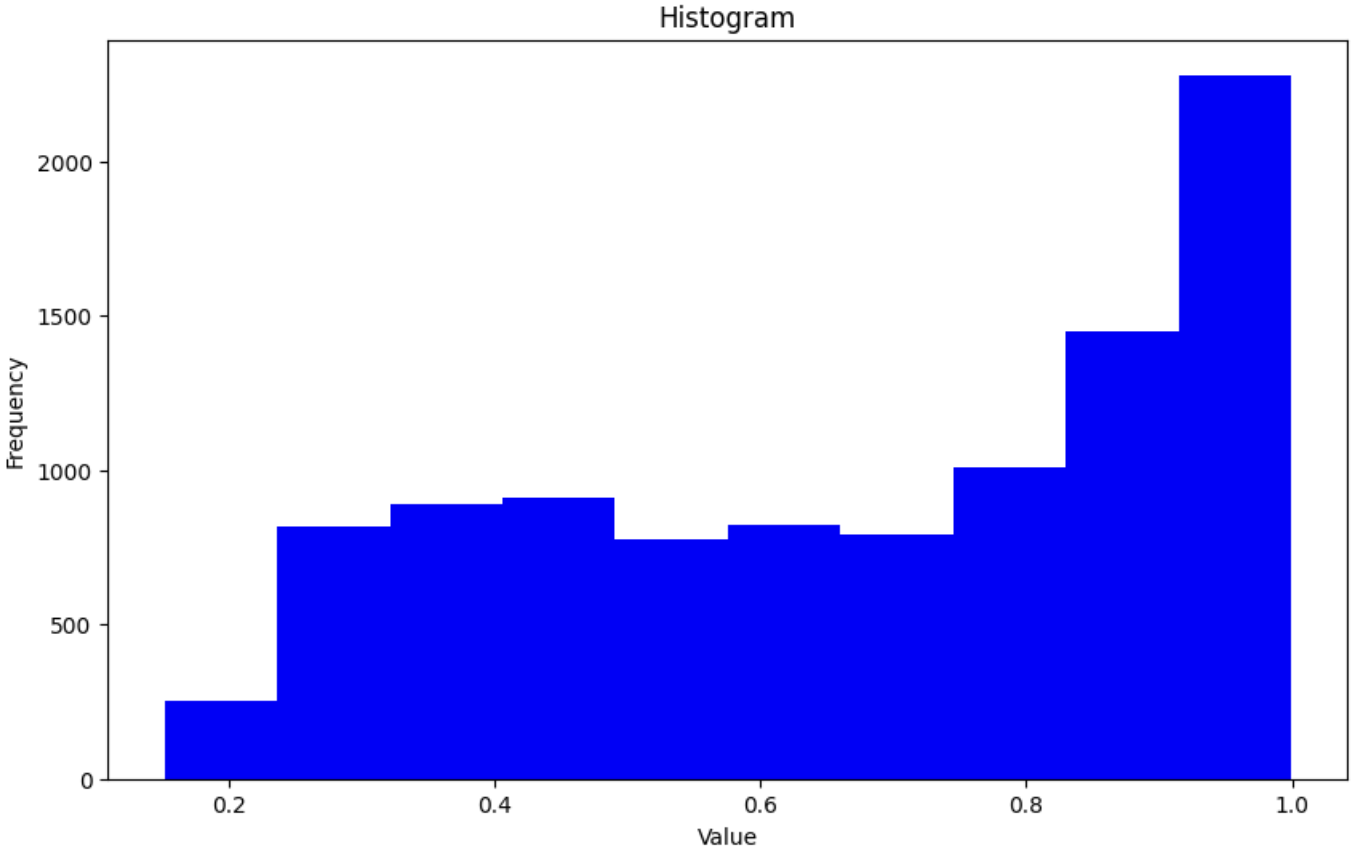

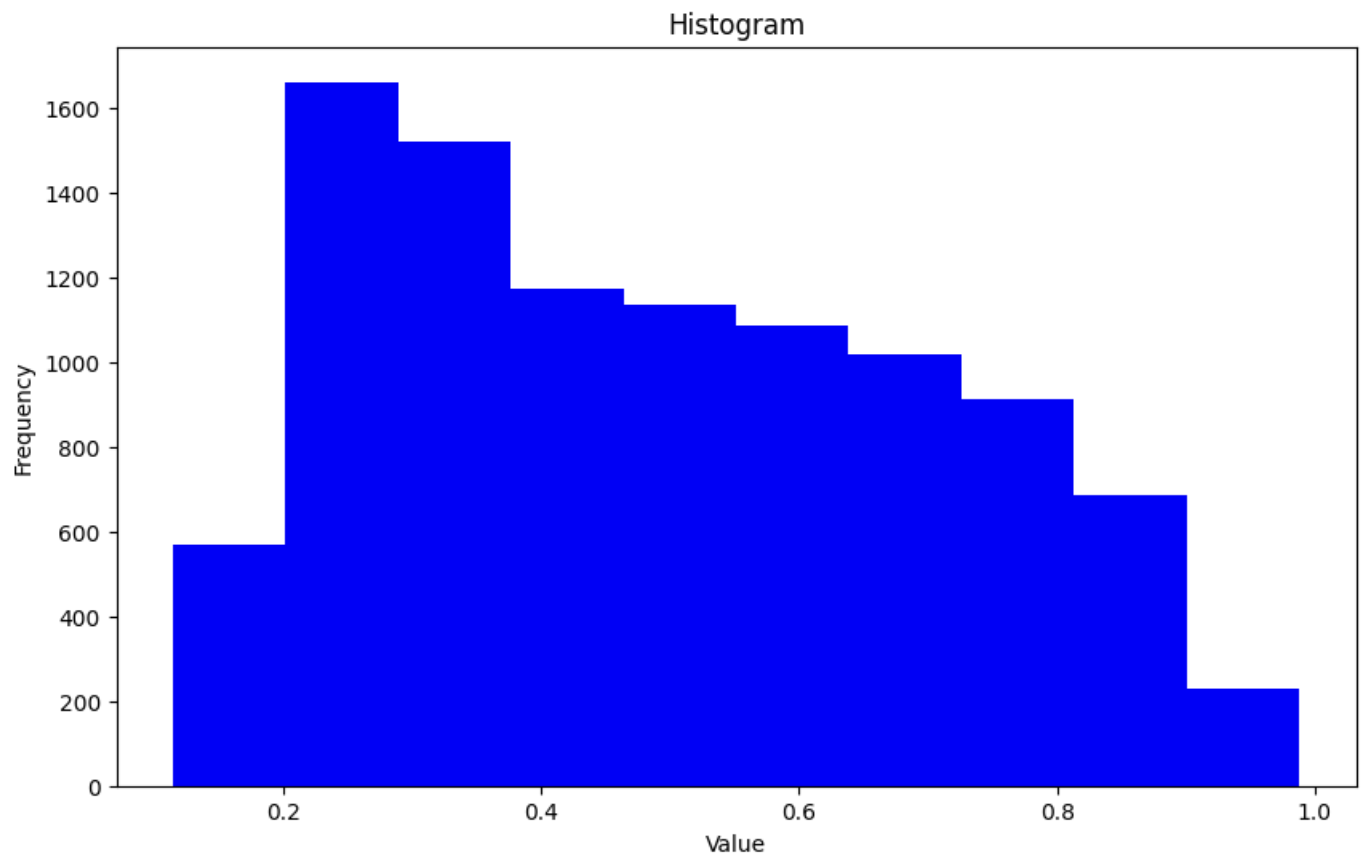

위의 그림에서 x 축은 Test Dataset의 Max Score의 값들을 의미하는 것입니다. Label Smoothing 미 적용 상태에서 적용함에 따라, Max Score 값이 1.0에 가까운 빈도 수들이 점점 고루 분포되는 것을 알 수 있습니다.
이상으로, Label Smoothing의 개념과 Tensorflow 2에서 적용하는 방법에 대해서 알아보았습니다.
감사합니다.